

With the ever-increasing amount of user-generated and third-party content taking over the internet, organisations have to continually moderate what’s being uploaded. But with the sheer volume of content going live daily, much of it is missed, requiring automated solutions to catch offensive or copyrighted material.
In a previous blog post, we did an introduction to what content moderation is and how some specific use cases could be tackled by leveraging AWS-managed AI services like Rekognition and Comprehend. While these services provide an easy and hassle free way to tackle some basic use cases of content moderation, they may not be adequate for more complicated use cases. The complexity of these use cases may be in the data and its multimodal nature, the labeling process, or even the type of model that needs to be trained. In this blog post, we’ll provide an overview of best practices for performing customised content moderation.
An example of more complicated content moderation
Let’s start with an example of a more complex content moderation use case, taken from Facebook’s Hateful Memes Challenge dataset. Let’s assume that we want to detect hateful content in social media. The first thing that comes to mind is to first extract text from images, then perform sentiment analysis on the textual content. But this approach is not going to work as the combination of textual and visual content becomes hateful, yet the image and text separately are not hateful at all.

This is when “contextualisation” comes into picture and the ability to extract “contextual features.“ Training the model on “contextualised” features allows us to build a model that succeeds in correctly detecting these hateful memes.
The sorts of things that can add complexity to content moderation
Multimodal content
As mentioned in the previous section, detecting hateful memes in social media could be a classic example of multimodal content moderation.

One other interesting use case, discussed with us by one of our clients, is the ability to monitor the multimedia communication channel between students and instructors in an online course to detect any type of misconduct. Use cases could vary from simply flirting, all the way to extreme cases of sexual abuse.
Obviously, the multimedia nature of the communication channel is the most challenging part of the problem. Not only should the content moderation system be able to process and analyse text, audio and video content of the session, it should also be able to detect complicated instances of violation in case the instructor or the student attempt to circumvent the basic misconduct detection mechanisms.
Multilingual content
Having multiple languages in the textual input could also be a challenge when dealing with content moderation use cases. The most simplistic approach to tackle this challenge would be to provide the textual content to out-of-the-box translation services and build the rest of the pipeline on the translated output.
Leveraging contextual information for subjectivity and confidence levels
As content moderation use cases become more and more complicated, using complementary contextual information could help in differentiating infringing cases from the ones that are ok. For example, object detection with a confidence level of 65% falls into the grey area of subjective infringement detection. However, if we take into account information like the user’s past behaviour and track record and realise that this particular user has uploaded infringing content in the past, it is highly likely that the content uploaded by the user is violating the code of conduct this time as well.
Lack of labeled data
Although multimodality in itself is quite an enormous challenge and requires employing various techniques to tackle the non-homogenous nature of features from different modalities, the problem is exacerbated by the fact that normally enough training data is not available. Therefore vertically scaling deep learning models (by just adding more layers) does not seem to be a feasible approach. As a result, some effort needs to be dedicated to data labeling prior to model development. Moreover, applying techniques like data pre-processing, enrichment and contextualisation would help in expanding limited features that could be extracted from a limited number of training samples.
Ways to create content moderation solutions
Generally speaking, AWS allows you to follow three main approaches for architecting ML solutions.
- ML-as-a-Service (MLaaS) approach: This approach does not require much knowledge of machine learning models, nor does it require any effort for training data preparation. If your use case allows tailoring out-of-the-box services (e.g. Amazon Comprehend, Amazon Translate, etc.) to achieve your goal, this is the easiest approach.
- Auto ML approach: This approach is based upon the idea of transfer learning, which allows you to fine tune an existing ML model and customise it for your use case. All you need to do is to prepare your training data and model training is done for you. Services like Amazon Rekognition Custom Labels are examples of Auto-ML approaches which we will touch on shortly.
- Custom model approach: This is the most flexible but at the same time most time consuming approach towards ML solutions. You need to have in depth knowledge of ML as well as the ability to prepare labeled data. This approach is recommended for use cases that could not be addressed using the two approaches above. Amazon Sagemaker allows building such ML solutions.
Combining multiple approaches to tackle complex content issues
Based on all the challenges that were mentioned above, we propose a number of different approaches that could help in building efficient systems for content moderation. Depending on the use case, one or a combination of these approaches could be designed and implemented to achieve the desired results.
Scenario 1 – Translate and moderate
As mentioned before, in case of dealing with multilingual content, we could build a pipeline that translates the non-English content using the AWS Translate service, then run the output to the moderation system. Besides, the AWS Translate service performs some basic moderation as part of translation which could be helpful for some downstream applications.

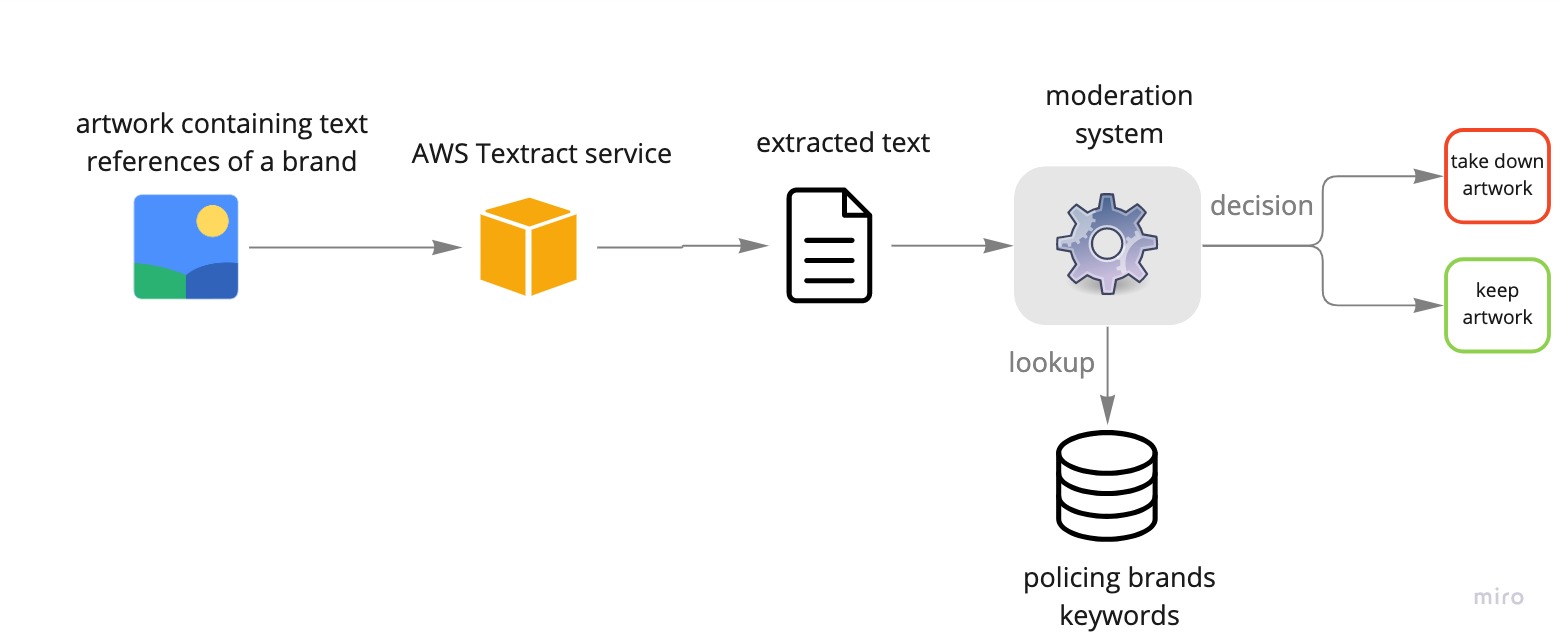
Scenario 2 – Image to text
Detecting infringing references of copyrighted brands is a use case that we tried to tackle as part of our engagement with a client. While looking into examples of infringing cases, we realised that in some cases, the brands and their references could be detected by simply extracting the text from images. All we had to do was to then check the extracted text against a list of brands against which we were policing the content.
Fine tuning existing models using Auto-ML
Scenario 3 – Custom object detection
Rekognition Customs Labels offers a handy Auto-ML framework for building a machine learning model that requires writing no code. It has support for machine learning use cases including classification, segmentation and object detection. The main effort for training a Rekognition Custom Labels model is annotating the training data, which will be explained in more detail in the data labeling section. Once the training data is annotated, training the model could be done as easily as clicking a button. The trained model then could be hosted and called within the AWS SDK.
Training custom models with multimodal features
In this section we discuss custom machine learning models that are developed to solve a certain problem that could not be tackled using MLaaS or Auro-ML approaches. Sagemaker provides support for most of the popular machine learning and deep learning frameworks like Tensorflow, Pytorch and MXNet, where ML practitioners could build their own custom models. It also offers the flexibility to build models using any arbitrary custom library that is not built-in through custom docker images.
Scenario 4 – Multimodal classification (late fusion)
Training multiple independent machine learning models on various modalities is a technique utilised by some machine learning practitioners, which helps in building a more powerful model overall. This technique is called ensemble learning and is categorised as a ”late fusion” approach in the sense that we are fusing the result of multiple machine learning models late in the process, treating each model as a black box. Combining the result of two models using a voting mechanism could yield a powerful ensemble model.

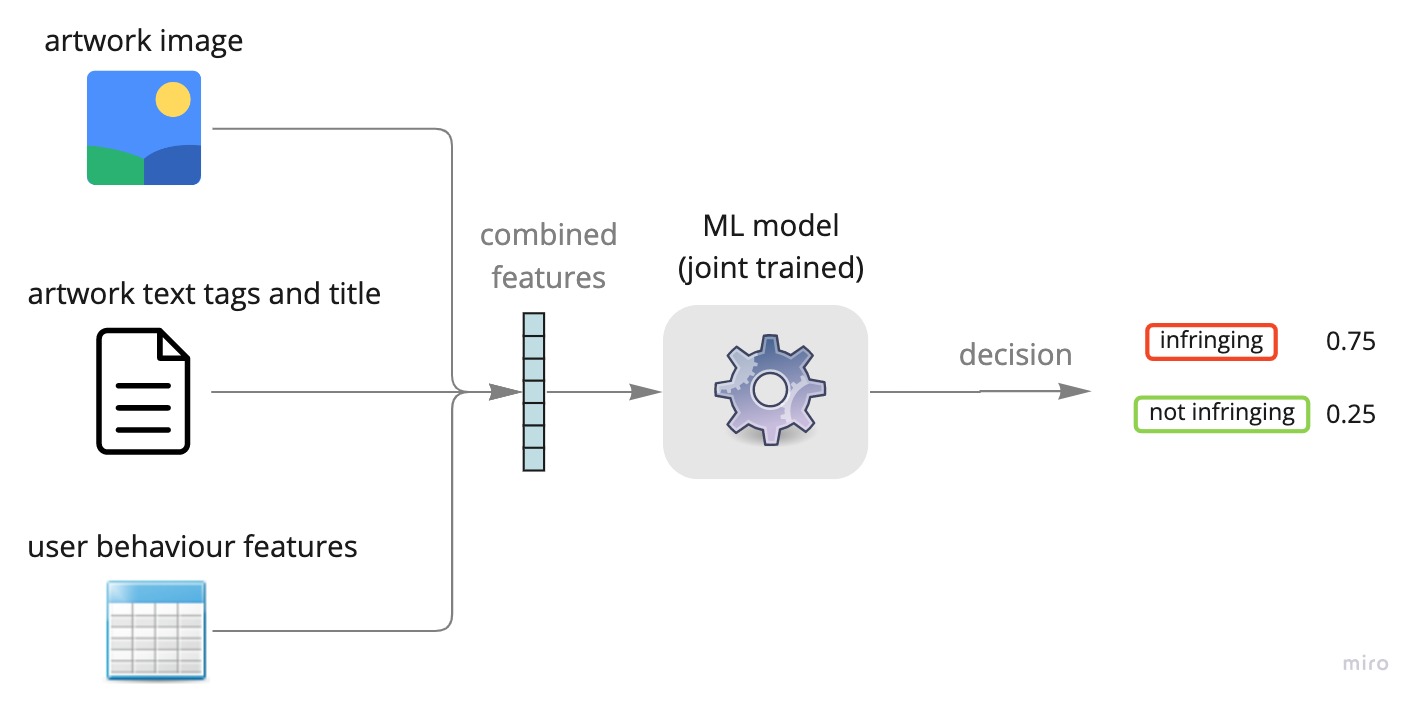
Scenario 5 – Multimodal classification (early fusion)
Conversely to the late fusion method explained above, in the “early fusion” approach, the features from various modalities (e.g. text, images, user behavior) are combined prior to model training and the “joint training” of the model on the mixture of features is carried out. A perfect example of such use cases is the hateful memes problem explained earlier, where the model has to be trained on the combined visual and textual features and the late fusion approach will not work in such a scenario.
Specifically, models that combine textual and visual features are called “visual language models” which rely on a complex model structure for joint training on textual-visual features. Examples of such models are MMF, ViLBERT. Joint training models on multimodal features could be expanded and generalised beyond textual-visual features and features from any arbitrary modality could be leveraged to boost the discriminative power of the machine learning model.
Labelling data for model training
Rekognition Custom Labels and Ground Truth
Custom Labels provide a user interface for labelling the training data and also prepare train/test splits. It shares the same UI as Ground Truth which allows sharing the labelling job among team members if needed.
Crowdsourcing Using Mechanical Turk
If the size of the training dataset is larger than a certain level, Custom Labels and Ground Truth provide the possibility of creating crowdsourced jobs that could be labeled using Amazon Mechanical Turk labellers. If you are very strict about the quality of your labeled data, Amazon also offers this premium service called Ground Truth Plus, where you define your label requirements and Amazon looks after all the steps involved in the labelling process.
Adding human verification step
As explained in several use cases, fully automated content moderation may be a bit challenging and therefore adding a human review step on top of the machine learning moderation result may be essential. AWS Sagemaker offers this feature called Augmented AI, through which one can define a human loop to allow verification of detection from a machine learning service. Human loop flows could be defined for built-in AWS services like Textract and Rekognition, as well as custom models built using Sagemaker.
Conclusion
Content moderation is an area that is rapidly growing given the enormous amount of content being generated on social media platforms and in the complex world of the internet. Content moderation is complicated due to its subjective nature and also the various information aspects that are involved in performing automated moderation. In this blog, we discussed how different machine learning approaches could be utilised to perform content moderation. A moderation solution could be designed by simply composing out-of-the-box ML services together. For more advanced use cases, leveraging transfer learning and fine-tuning a pre-trained model could lead to building the desired model, an approach that is referred to as Auto-ML. Moreover, in cases where utilising more complex features or model architecture is necessary, a custom model could be trained from scratch that suits the needs of the specific use case the user is dealing with.
References
[1] How can AI and ML keep moderators and users safe from harmful content?
[2] Facebook Hateful Memes Challenge
[3] Multimodal Automated Content Moderation
[4] Lu, Jiasen, et al. “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.” Advances in neural information processing systems 32 (2019).
[5] Facebook MMF