

Data is the foundation that underpins countless businesses. But that doesn’t mean to say this information is being captured and collated as efficiently as it could be. Some organisations continue to rely on manual and expensive processes, which are both time-consuming and error prone.
This is where something like Intelligent Document Processing (IDP), which refers to the collection of data from unstructured, semi-structured or structured documents, can help.
In this blog post, we’ll explore Amazon Textract, a Machine Learning (ML) IDP service that extracts text – whether typed or handwritten – from documents and images. Textract can be used through the AWS console or by using Textract SDK, which is available in a variety of languages like Python, Java, Javascript and Go.
Textract features
There are multiple features in Textract (Words, Lines, Forms, Tables, Queries), so we thought it was a good idea to preview them. These features will be our building blocks as we evaluate a Textract solution for certain business problems. In addition, we will also consider the cost and accuracy for the listed Textract features.
Word method
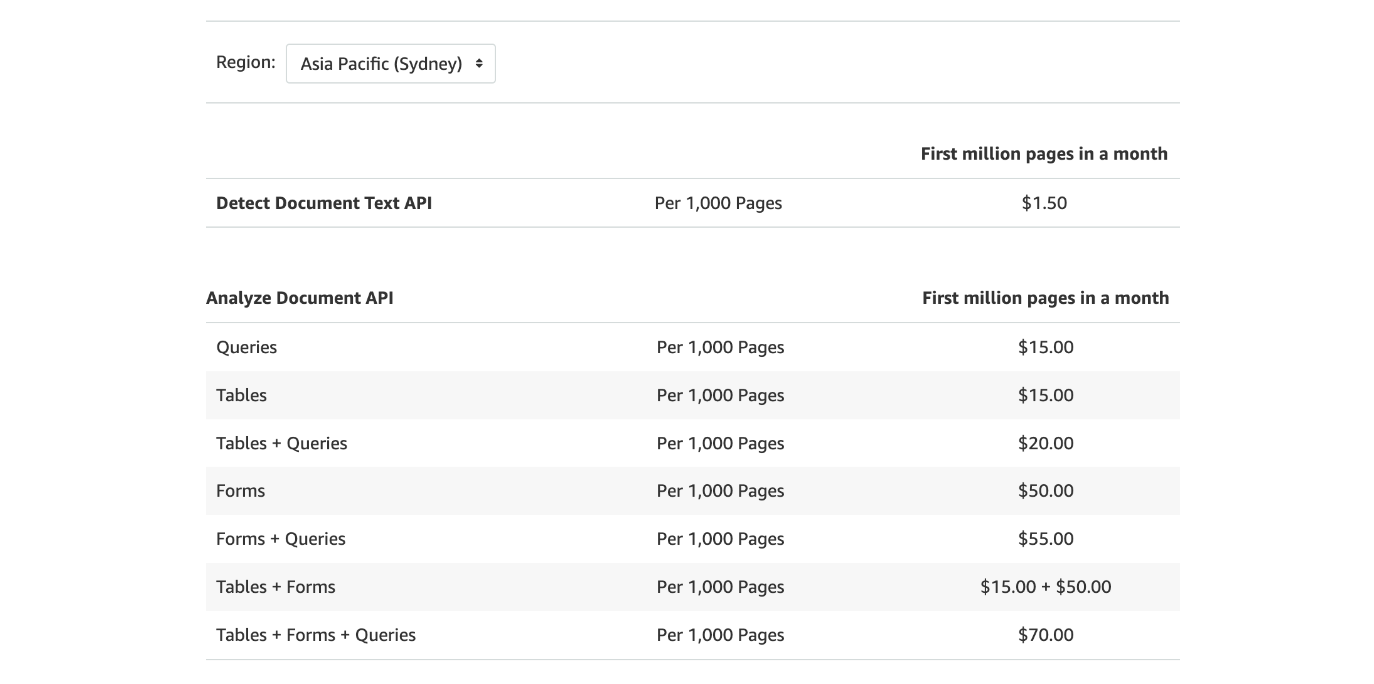
Probably the simplest feature is what we can call the `Word method`. If detecting a word without any relation to other words is sufficient for your use case, then this would be one of the cheapest and most straightforward ways to detect text. A “Detect Document Text” call costs $1.50 per 1,000 pages.
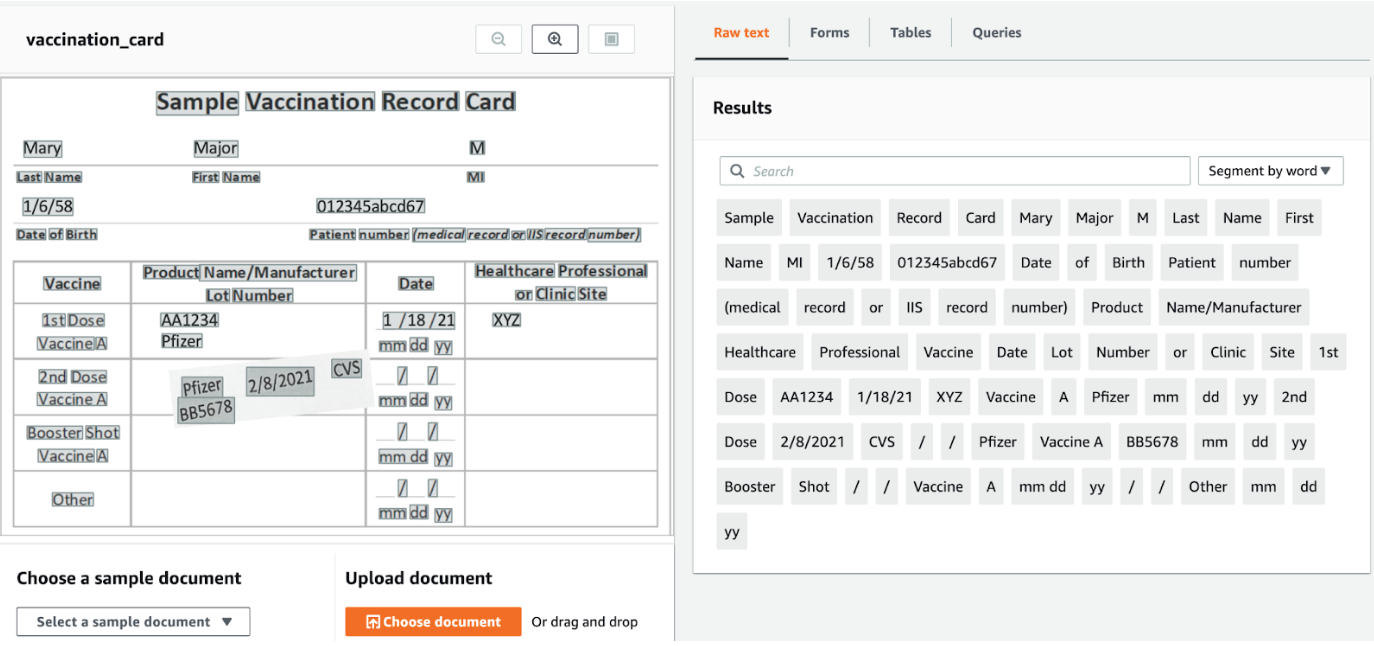
Line method
It’s likely that for our use case, we’ll need more than words in isolation. So, the next step may be to find out which words are grouped closely together in a line.
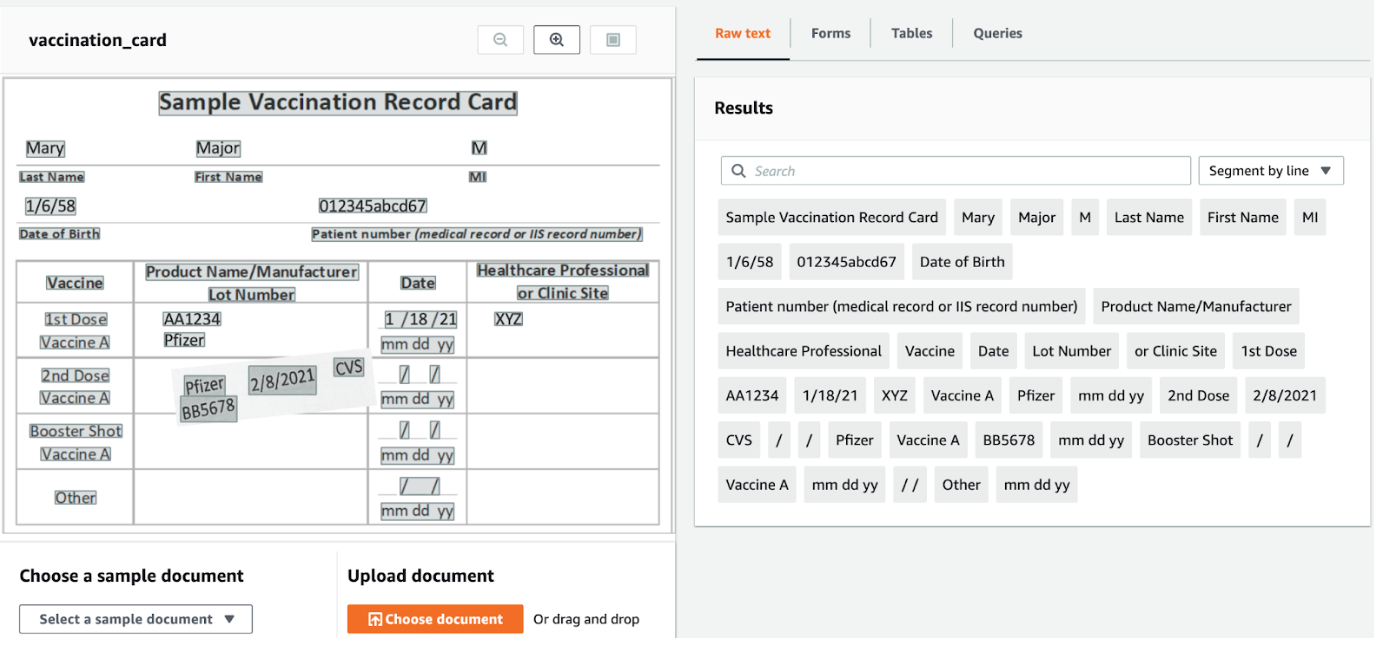
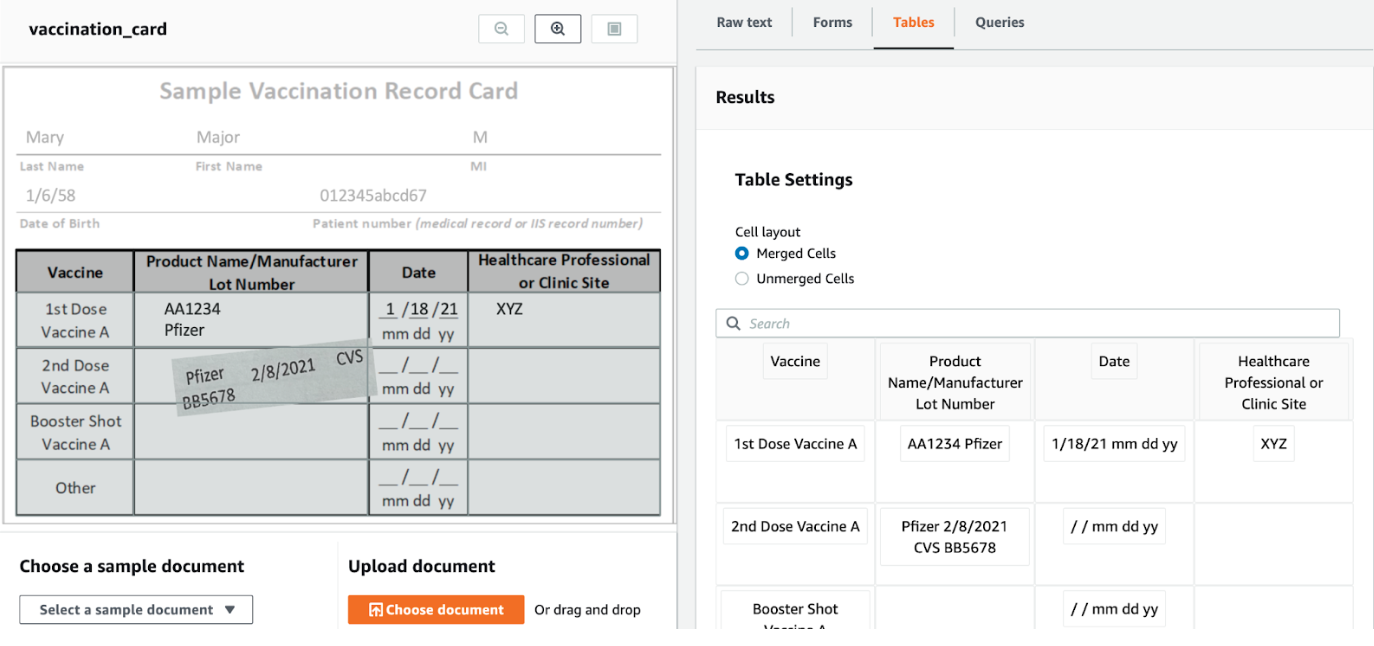
Table method
For a more structured form, Textract also has a feature that can detect tables. Although this costs $50 per 1,000 pages, it provides information on the location of the words relative to the detected table. For example, this method can detect that the group of words “Product Name/Manufacturer Lot Number” belongs to a cell in the table. Not only that, this method can detect that the cell is a header cell too.
The output response from the Table method also contains information similar to the response coming from the Word method and Line method. So, if we want to use both the Table method and Line method for the same document, a cost-effective way is to just use the Table method only and then post-process the Table method response to get Line method related information. This strategy only calls the Textract service once.
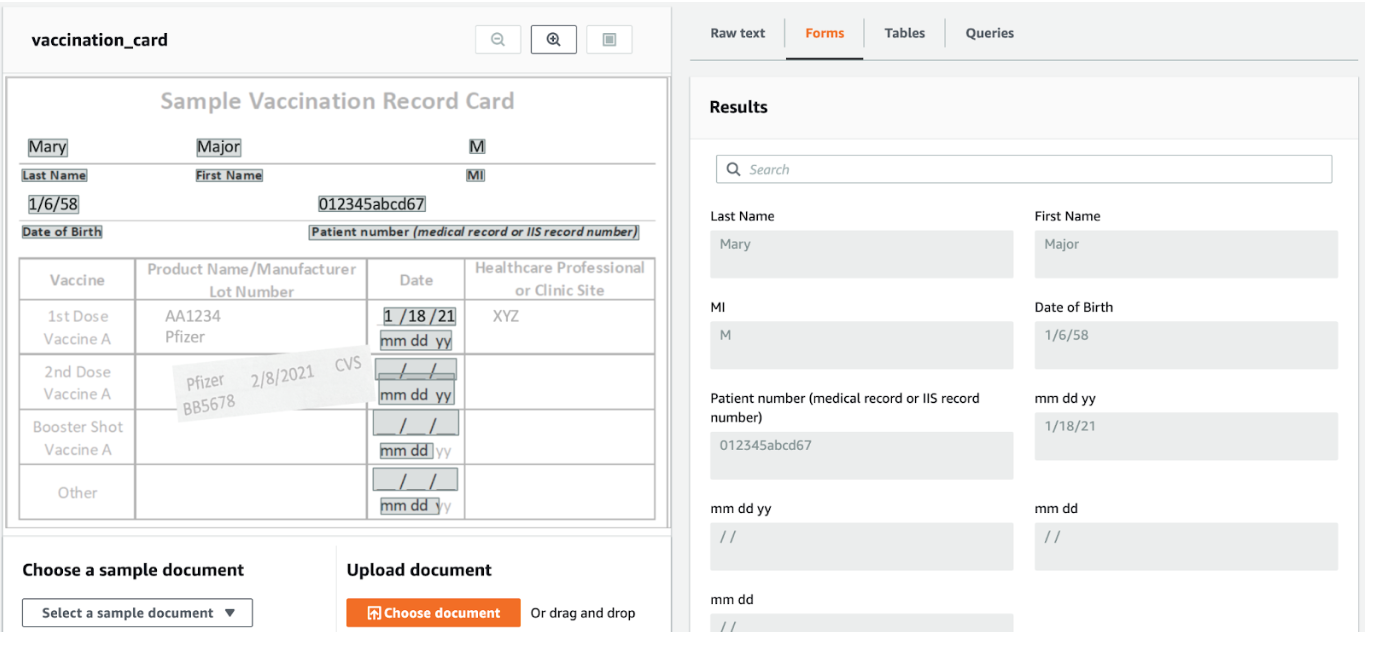
Form method
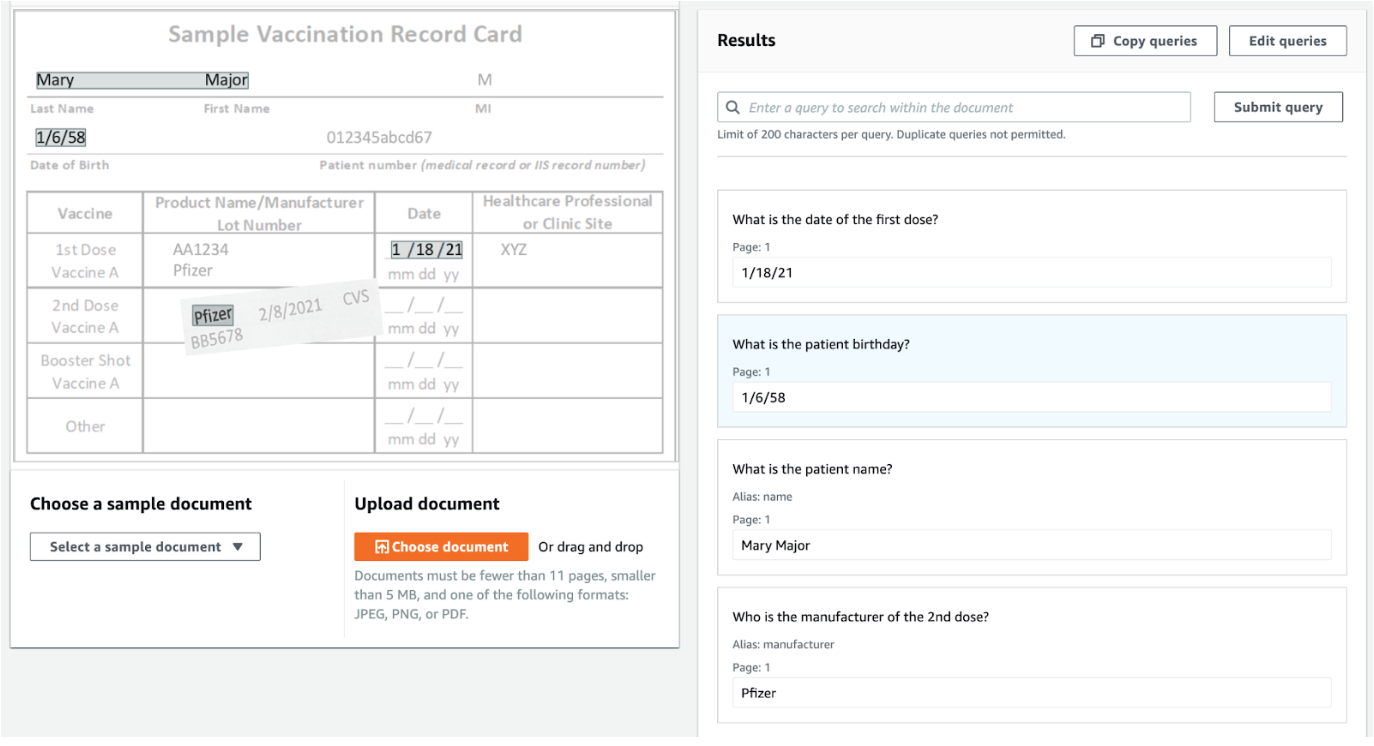
We can also get the structure based on key-value pairs. For example, “Last Name” is a key that is paired with the value “Mary”. This method costs higher than the Table method ($55 compared to $50 for 1,000 pages), but it does provide all the key-value pairs in the document.
In the Form image, notice how the “Last Name” key detected the value “Mary” even though they are not on the same line. This is another advantage of the Form method compared to the Line method. But again, it’s usually the cost that prohibits the use of this method. We’ll explore another method (Query method) where it can detect some key-value pairings – only the relevant pairings we specified.
Queries method
Queries is a recent addition to Textract. We find that this way of querying the document using natural language opens up opportunities for IDP. You can even add queries like how you’d perform a Google search and the questions are uploaded in the document through a spreadsheet. It will then search the closest answer in the given document.
For example, even if the birthday key is “Date of Birth” for “1/6/58”, Textract Queries was able to answer a differently worded but related question “What is your birthday?”, giving the value “1/6/58”. The questioning can also combine key-value pairs that may otherwise have been separate. For example, “What is the patient name” provided the answer “Mary Major” combining the “First Name” value and “Last Name” value. Lastly, it’s able to detect some structure in the document too. If we ask “What is the date of the first dose?” then it needs to find the intersection of the Date column and the First Dose row, giving us “1/18/21”.
The Queries method uses a combination of visual language and language cues to provide an answer with relatively high accuracy. This could be helpful especially for documents with varying format representations. All rosy, yes, but there’s a limit of up to 15 queries for synchronous operations in the Sydney region. So, it’s best to prioritise what kind of questions we’ll ask. Or if we really need more queries, we can call the Queries method again with a different set of questions (bear in mind, this will incur additional costs).
Textract in the wild and business use cases
Simply having one predefined way of using Textract for business use cases isn’t an ideal way of extracting relevant information in terms of cost and accuracy. The scenarios below should give you a good idea why it’s important to have a bespoke strategy or at least a spike. Let’s look at a few strategies around different verticals that can use Amazon Textract for ML-powered Document Processing.
Accomodation and food services
Let’s start by focusing on food labels and detecting the nutrient information table.The table method is a good candidate because it can detect the tables and could possibly just need workarounds in post-processing to get the required information. Next, we can try the Queries method with queries like “What is the protein per serving?” The query detects a few, but you’ll notice that there are still mistakes like that in the “Carbohydrate” detecting ‘8.1g’ instead of the correct value, ‘27.5g’.
The sample food label below shows bounding boxes for the table detected (green on left) and answers to some queries on the nutrition table (blue on right).
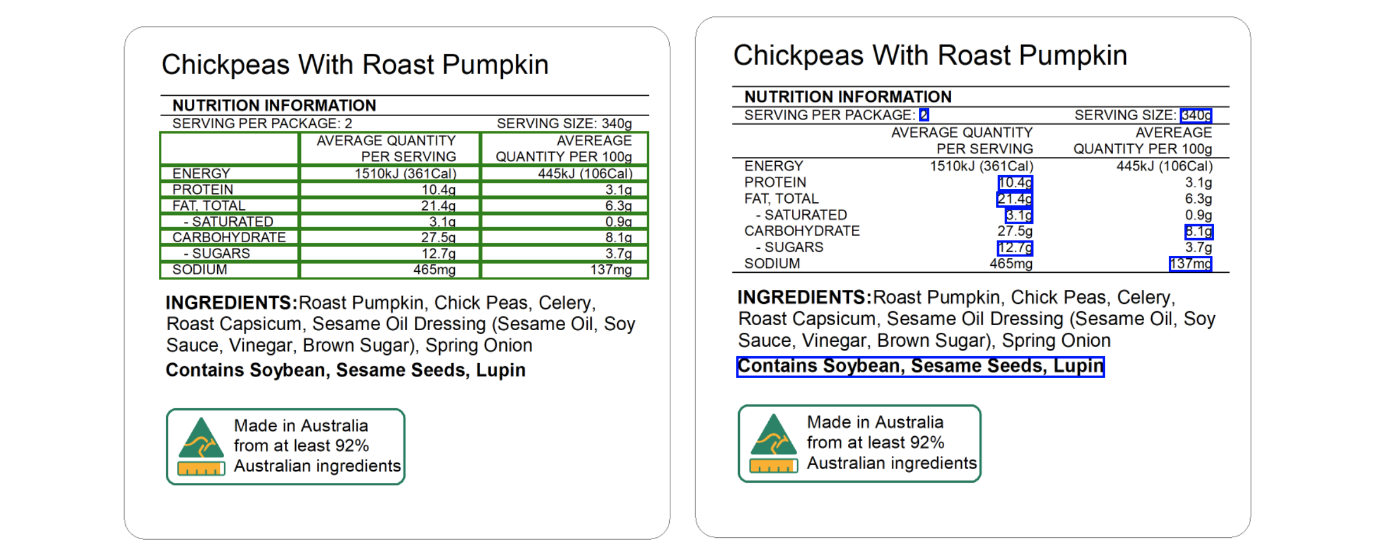
However, it’s possible that a table may not be detected on a blurry image. It’s also possible that the nutrition table may have a different way of presenting the value like the ‘Sugars’ in a Philippine product below. You’ll notice that the table will likely not detect ‘Sugars’ in the same column. And if it’s a blurry image, the table might not even be detected as shown in the example. In addition, if we wanted to detect the ‘9g’ in ‘Sugars’, it would be on the same column as the ‘Sugars’ text and would need post-processing. But if we use the queries method, we may find the value ‘Sugars’ as ‘9g’. These sample scenarios may lead us to think about using the table method first, but if the values we want in the table method cannot be detected, we can use the queries method as a fallback.


Financial services industry

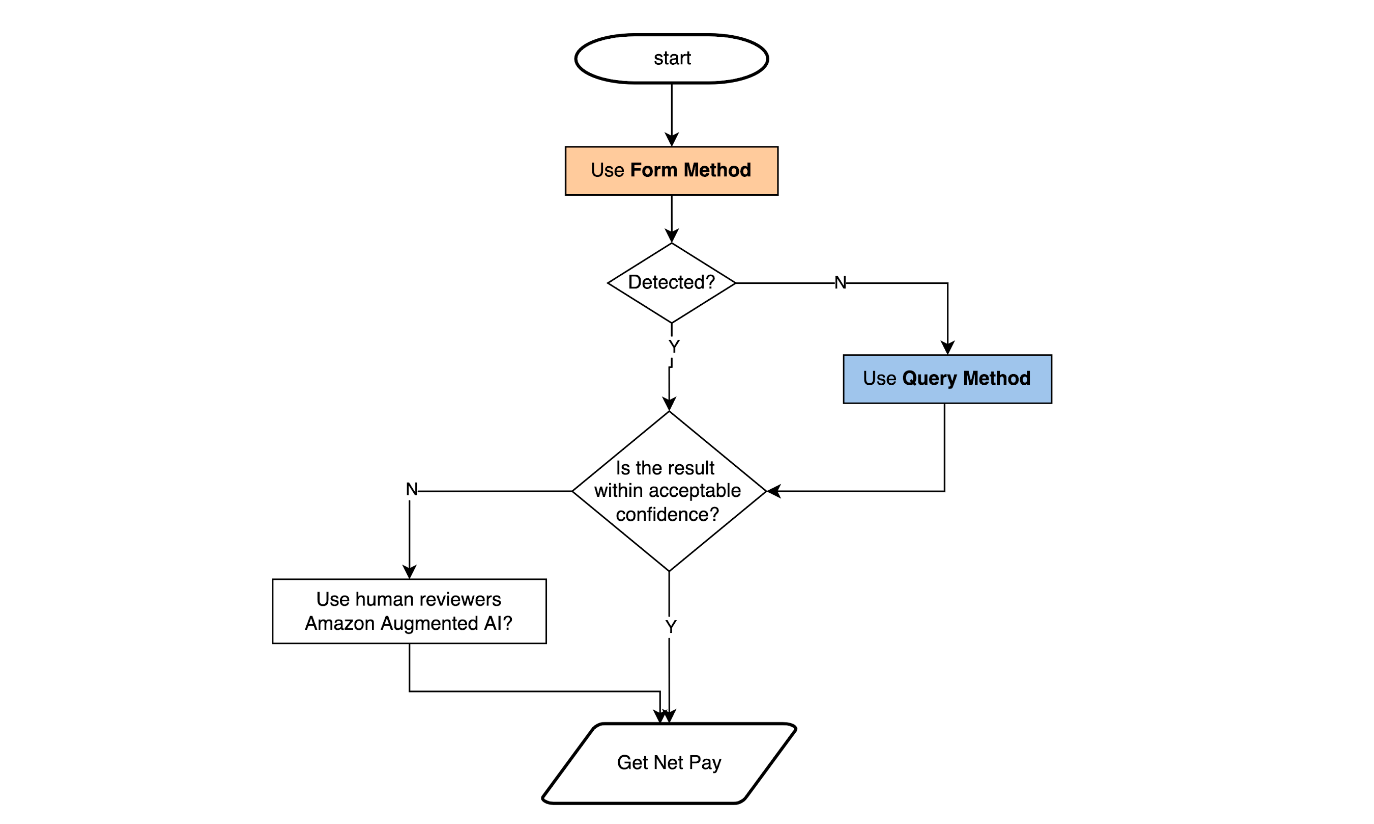
If we only need to detect a few key things like the pay, we can also use the Queries method to detect these values. Because these values, like detecting the amount of money, may be critical, we can create a bespoke solution so that we also get the confidence level of the detected value. If it gets a low confidence level, say 40%, then a human reviewer can look into these documents more closely. We can see how a combination of Forms, Queries and human reviewers can be combined for a solution. You might notice this solution may be different from the Accomodation and Food Services example we discussed above.
Retail industry
We can also look into tracking receipts. Sometimes it’s even possible to detect handwriting like the ones displayed below. There’s also a specific API called `Analyze Expense` that can be used for analysing invoices and receipts. This would cost about $10 per 1,000 pages. If cost is not too much of an issue, we can use the confidence level to be a marker and send this for human review or use another Textract feature method like Forms.


Real estate and property industry
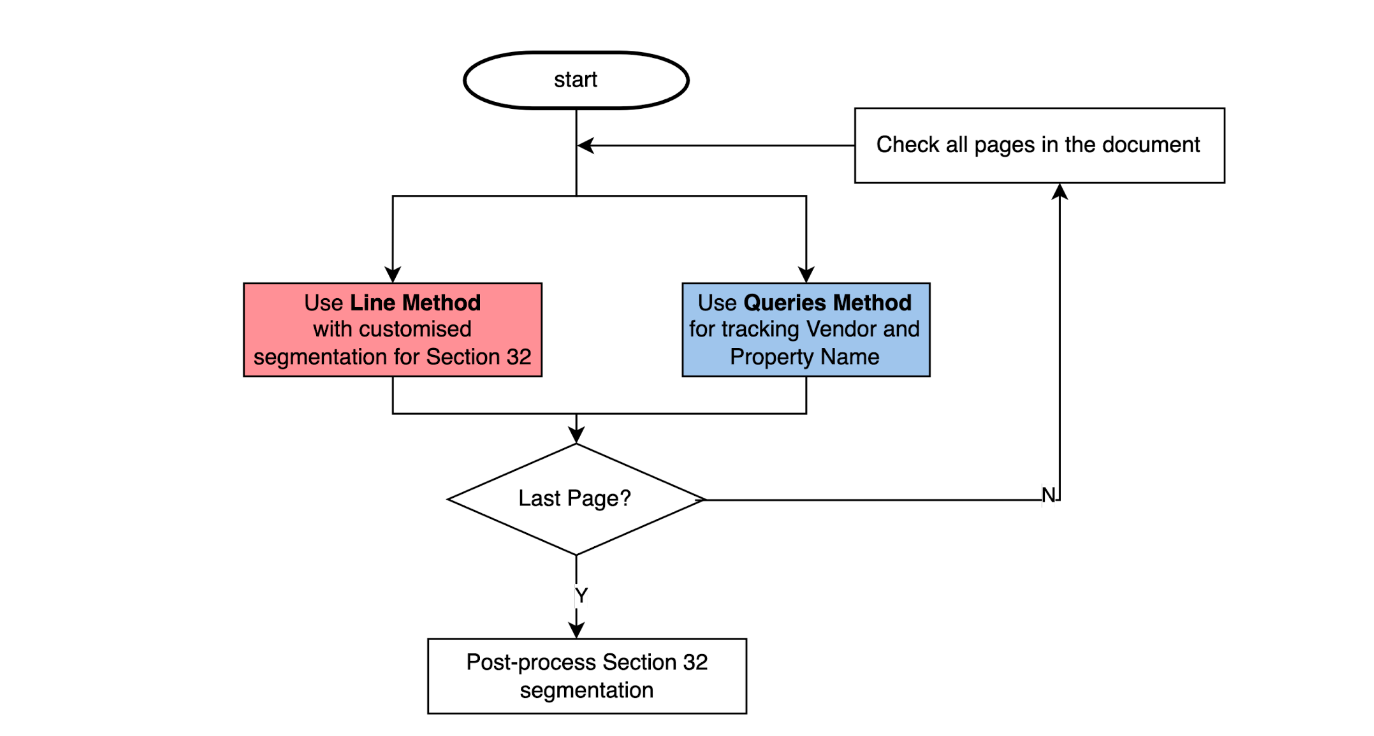
In real estate, a business may want to retrieve the Section 32 from multipage documents. In the State of Victoria, Section 32 in the Sale of Land Act requires vendors selling real estate to provide written information to the purchaser before a contract may be signed. However, there’s no specified format for such a document. This requires a different strategy as we will try to detect the information of interest from multiple pages of the document. It is even possible that the information we are after may be found on a double column page and it’s only found on the right column. For this, maybe the Line method might work as long as there is a proper segmentation such as the detection of the left and right indents. If additional information is needed, say for the Vendor and Property name, possibly the line method can be used. But maybe another complementary method like Queries might work here too.
Government
The processing of visa applications can be slow, and a possible way to help with this could be the detection of forms like birth certificates from different countries. If only a few pieces of information are needed from documents with varying formats, then the Queries method may do the job. We can make this more robust by also adding in key-value pair checks using the Forms method. And with low confidence scores, a human reviewer could help with this.


More tips in using Amazon Textract
Let’s wrap up this blog with some practical tips.
Importance of spikes. A spike will likely be needed to demonstrate what kind of Textract combination methods work. There may also be customised solutions around the use cases. For example, if the sample business has customers that provide low-quality images, the images may need preprocessing such as rotation and skew correction before using Textract services. Alternately, it may require multiple interventions like pre-processing images, or asking for the client’s customers to take better photos with instructions.
More on pre-processing documents. We’ve already mentioned how pre-processing might improve the results from the Textract service, but this also means that post-processing those results can also be made much more easily. For example, if we’d like to segment paragraphs using indents, those indents would be easier to segregate into important ones when text is aligned horizontally.
Use confidence levels. Textract provides an automated way of detecting values, but there are situations where it may be critical to detect information correctly. We can use the confidence level attached to each and work out the threshold where we’ll send the document to human reviewers for checking. This reduces the need for manual review of all tasks, or indicates to the reviewers which documents must be checked. To summarise, in cases where an incorrect response can be costly, make sure you have a person reviewing the results. This is possible with other services such as Amazon Ground Truth, AugmentedAI and human intervention.
Costing considerations. Detecting words or lines of text is cheaper than using methods like Tables, Queries and Forms, but there are also workarounds to mitigate costs. For example, if we use Tables and Queries for the same call, it’s only $55 instead of a combined $100 per 1,000 pages. In addition, if we need to use the word method along with the line method, we can just reuse the response from the Textract call and post process to get the values we need.
Use IDEs for ML for fast experimentation. There are different integrated development environment (IDE) options available, and we currently use the Amazon SageMaker Studio for fast experimentation since we already use AWS infrastructure. Aside from integration with online repositories, the interface is quite familiar to data scientists that may be using Jupyter notebooks for experimentation.
Have fallback methods. There are different Textract methods we can use, and if we want a more robust way of detecting values, we probably need additional methods. Depending on the use case, we can prioritise one method, while another method can be used as a fallback if an expected item is not detected.
Parting Words
Textract is a straightforward way to jumpstart your IDP requirements thanks to its various features. But getting the most of this service typically means employing a combination of features specifically tailored to your use case. It really depends on the application, costing and accuracy needed.
A Textract feature approach may not always get the answer 100% right all the time, but a combination of methods, as well as having a fallback, can get you moving fast and at the same time, provide a service robust enough to meet your business needs. Don’t forget we are always here to help!